BERT微調【歌詞】
歌詞微調不再糾結於單個字詞的意思,而是將「整首歌的歌詞文本」視為一個完整的語意單位。 歌詞具有敘事性,情緒會隨時間演進有變化,因此透過BERT的全域自注意力機制,能識別出不同段落(主歌、副歌、橋段)之間的邏輯與情緒流動。
舉例:
(第一段)「天空下著雨,我獨自在街頭徘徊。」(局部:憂鬱)
(第二段)「直到遇見你,陽光終於穿透雲層。」(轉折)
(第三段)「現在我懂了,所有的等待都是值得的。」(最終:滿足)
BERT模型讀完全文後,會發現情緒從【負面】轉向【正面】,最終判定這首歌為【平靜/滿足】,而非被第一句的「雨」或「獨自」給誤導。
♬判斷方式
第一段
天空下著雨,
我獨自在街頭徘徊。
第二段
直到遇見你,
陽光終於穿透雲層。
第三段
現在我懂了,
所有等待都是值得的。
♬混淆矩陣分析
此圖為歌詞微調模型的混淆矩陣,用來呈現模型在四個情緒象限(Q1~Q4)上的分類表現。
四象限預測正確數量:
Q1:24筆
Q2:20筆
Q3:24筆
Q4:12筆
- 總樣本數:108
- 預測正確筆數:80
- 成功機率:74.07%
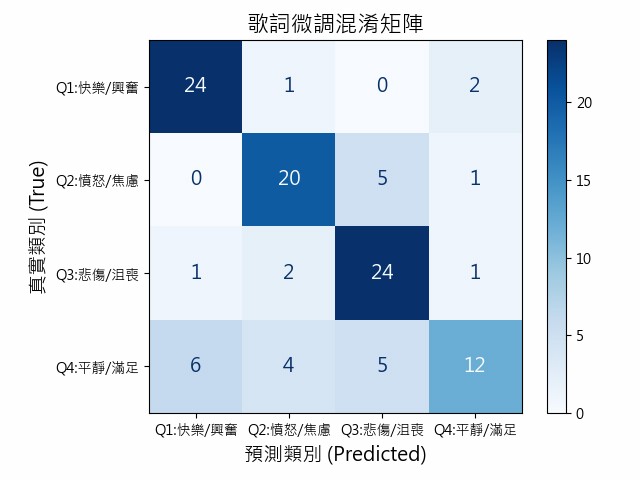
圖9、歌詞微調的混淆矩陣
Q1(快樂/興奮):辨識力極高且誤判極少,精準捕捉正向高激起的語言規律,為模型最優類別。
Q2(憤怒/焦慮):維持高度辨識穩定性,主誤差源於負面語境下「情緒強度」的判定干擾維持了高度的辨識力,主要的誤差在於5筆誤判為Q3。
Q3(悲傷/沮喪):從最初模型的39%到現在的85.7%。理解了歌詞中關於「失落、消極」的長文本語境。
Q4(平靜/滿足):雖然預測狀況不如另外三類,但能正確識別出近半數的平靜歌詞。反映出「低激起」情緒在正負向判定上的困難性。
整體而言,模型以Q1表現最佳,Q2與Q3仍有少量混淆,Q4辨識較弱,但整體分類能力已具穩定性並持續改善。