BERT微調【情緒類別】
傳統情緒詞典的限制在於,詞彙通常被固定標記在單一情緒類別中,無法隨語境變化而調整。為了解決這個問題,本研究導入 BERT 作為詞典的「語境雷達」,讓模型能根據上下文理解詞彙在歌詞中的實際情緒。
- 傳統詞典:「眼淚」這個詞被貼上了悲傷的標籤。只要歌詞出現眼淚,系統就會判定這首歌是難過的。
- BERT模型:讀取語境並進行動態微調。當模型讀到上下文關係,例如:「終於等到你,流下了眼淚」,雷達偵測到了「終於」和「等到」代表圓滿的詞彙,理解當下的氣氛是喜悅的,於是把「眼淚」動態歸類為【快樂】(喜極而泣)。達到去標籤化,由它身處的歌詞環境來決定它的情緒身分。
♬判斷方式
首先,模型會讀取歌詞中的關鍵詞(例如「眼淚」),並將其輸入到 BERT 模型中。接著,BERT 會根據整句歌詞的語境進行理解,例如判斷是「久別重逢」還是「失戀分手」的情境。在理解語境後,模型會偵測關鍵詞周圍的語意線索,例如「終於」、「等到」或「離開」、「只剩下」等詞,用來判斷當下的情緒方向。最後,系統會依據語境進行動態情緒分類,將原本可能被固定為「悲傷」的詞(如眼淚),重新判斷為「快樂/感動」或「悲傷」,讓情緒判斷更貼近真實語意。
淚
為悲傷
重逢
流下了眼淚…」
分手
只剩下眼淚…」
微調
[終於]、[等到]
[快樂/感動]
[離開]、[只剩下]
[悲傷]
♬混淆矩陣分析
此圖為情緒類別微調模型的混淆矩陣,用來呈現模型在四個情緒象限(Q1~Q4)的分類表現。
四象限預測正確數量:
Q1:16筆
Q2:23筆
Q3:8筆
Q4:2筆
- 總樣本數:108
- 預測正確筆數:49
- 成功機率: 45.37%
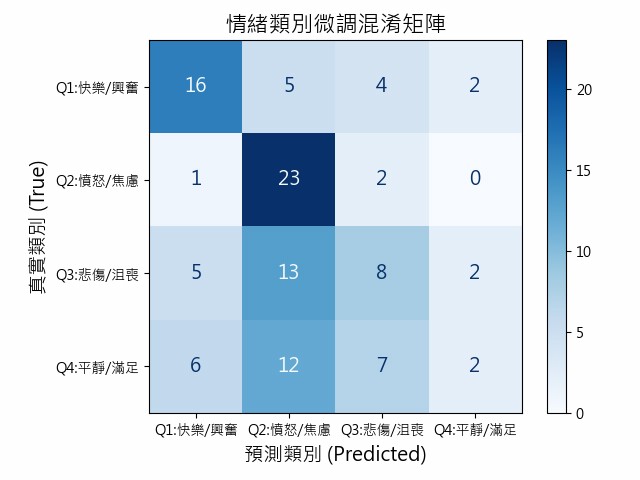
圖7、情緒類別微調的混淆矩陣
在四個象限中,Q2(憤怒/焦慮) 表現最佳,正確預測達 23 筆, 顯示模型對於高能量負向情緒的辨識能力最強。
Q1(快樂/興奮) 次之,正確預測為 16 筆, 顯示對正向高激起情緒的良好辨識力,能有效區別出具備積極能量的歌詞文本。
Q3(悲傷/沮喪) 表現較弱,正確預測為 8 筆, 其中有 13 筆 被誤判為 Q2, 顯示模型容易將「低能量負向情緒」誤判為「高能量負向情緒」, 反映在負向情緒中Arousal(強度)判斷較不穩定。
Q4(平靜/滿足) 表現最差,正確預測僅 2 筆, 且有 12 筆 被誤判為 Q2, 顯示模型傾向將「低能量正向情緒」誤判為「高能量負向情緒」, 在Valence(正負)與 Arousal(強度)兩個維度上皆出現偏移。
整體而言,模型對於高強度情緒(特別是 Q2)的辨識效果較佳, 但在低強度情緒(Q3、Q4)的判斷上仍存在明顯困難, 尤其容易出現情緒強度與正負方向的混淆。