NLP介紹與模型比較
♬自然語言處理(NLP, Natural Language Processing)
自然語言處理 (Natural Language Processing,簡稱NLP)是融合語言學、電腦科學與人工智慧的一個領域,主要是讓電腦能夠理解和使用人類的語言。核心架構由「自然語言理解」與「自然語言生成」交織而成,將複雜多變的文字資訊轉化為機器可處理的邏輯語義。 透過NLP技術,電腦可以讀懂文字、分析句子,甚至自己生成文字或回答問題。例如: 聊天機器人、翻譯軟體和情感分析等功能
♬模型比較
- 傳統RNN模型:是一個字一個字往後處理的序列模型,運算成本比較低,但在文章變長的時候,前後文的資訊比較容易流失。
- BERT模型:是基於 Transformer 的 Encoder 架構,主要用於語意理解相關任務。其最大特色是能夠同時考慮前後文資訊(雙向理解),因此在文本分類、情感分析等任務中表現優異。
- T5模型:是 Encoder 加 Decoder 的架構,除了能理解文字,也能產生文字,任務彈性較高,適合用在翻譯或摘要,不過相對來說模型比較複雜,也比較吃運算資源。
- GPT模型:是 Decoder 架構,主要強在文字生成,像是對話或內容創作這類任務。
在自然語言處理(NLP)領域中,存在多種不同的模型架構,每種模型在設計理念與能力上皆有所差異。因此,在實際應用之前,進行模型比較是非常重要的一步。 以下是幾種常見的NLP模型架構:
| 模型類別 | 核心架構 | 功能 | 優勢 | 使用情境 |
|---|---|---|---|---|
| 傳統RNN模型 | RNN-based | 序列建模 | 適合小模型、可處理序列資料 | 時間序列預測、語音處理、簡易文本序列 |
| BERT系列 | Encoder-only | 分類/理解 | 擅長語意理解、分類精準 | 文字分類、情感分析、問答系統 |
| T5系列 | Encoder-Decoder | 理解+生成 | 擅長多任務泛化 | 翻譯、摘要、複雜指令任務 |
| GPT系列 | Decoder-only | 生成為主 | 文本生成最強,續寫流暢 | 文本生成、故事創作、對話生成 |
綜合比較之後,我們的目標是歌詞情緒分類,屬於語意理解,再加上我們的硬體資源有限,沒有辦法跑太複雜的模型,所以最後選擇使用 BERT 模型。
♬BERT
BERT(Bidirectional Encoder Representations from Transformers)是Google以非監督的方式利用大量無標註文本「煉成」的語言代表模型,其架構為Transformer中的Encoder,且是堆疊多個Encoder層,並利用「自注意力機制」,讓模型在處理每一個字詞時,能同時捕捉上下文資訊,產出具備深層語境意義的向量代表。
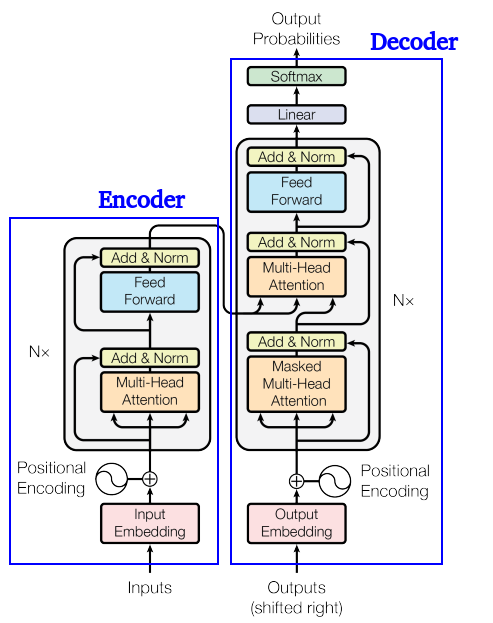
圖3、Transformer
♬BERT微調
我們選用chinese-bert-base的預訓作為基礎模型,並採取遷移學習的方式,維持預訓練模型的主體架構,且只需在最後加上一層簡單的Output Layer (分類器),藉由監督式學習與標註資料的投入,能讓模型在短時間內學會情緒特徵,達到分類情緒效果。
圖4、BERT微調